
Data is the new oil, and artificial intelligence is the new electricity! Both oil and electricity took the 19th-century world by storm, transforming the lives of billions of people and shaping the course of the future. Data and AI will do the same for us in the 21st century, say the experts. It’s a loose and shallow analogy, but it does what it’s supposed to do—conjure excitement for the cost saving, revenue-generating potential of the technology among corporate executives. What doesn’t excite corporate executives is having to use workers to build this new technology. Workers are missing from the “data is the new oil” analogy. Oil didn’t get up in the 19th century and transform the world by itself; workers in the process of extracting, refining, transporting, storing, and using the oil did. Same with electricity. So who are the workers who use data to create AI, how do they do that, and why?
What isn’t AI?
To understand the nature of what goes on behind the scenes, we must first understand that AI is not a particular technology. The late computer scientist John McCarthy, one of several scientists who coined the term “artificial intelligence” at what is considered the founding conference of AI in 1956, defined AI as “the science and engineering of making intelligent machines, especially intelligent computer programs.” Scholars from several fields have defined intelligence in many ways according to its many aspects, but there is still no widespread agreement on a definition of intelligence in general. For each particular aspect of intelligence, there may or may not be a technology created to mimic it. We have built many technologies over the past 70 years to try to make intelligent machines. Some of those technologies have been applied more successfully than others. Twice in its history, research funding, job openings, and media buzz associated with AI dramatically declined, in part because specific technologies failed to deliver on the promise of AI.
The product behind the AI boom
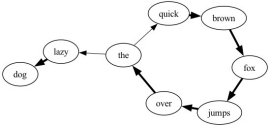
Figure 1: A very simple probabilistic model (Markov model) of the sentence “the quick brown fox jumps over the lazy dog.” The more likely the next word is to follow the first, the thicker the arrow.
Figure 2: The same probabilistic model based on the text of the Communist Manifesto.
We also have to understand the technology that led to the most recent AI boom: large language models. Language models are computer programs that try to generate language in a way that seems plausible. Think auto-complete on a cell phone’s keyboard. Large language models take that process to another level, generating entire paragraphs or documents in response to a question. Take ChatGPT, the chatbot built at OpenAI, as an example. GPT stands for generative pre-trained transformer, a specific type of large language model. In order to do what it does, the model must be trained, essentially dialing its knobs to get the correct output. This happens in one of two ways:
- The program must detect the patterns of language by itself, based on the statistical properties of massive amounts of text. This is called unsupervised learning.
- People have to manually create many examples of proper language usage to feed into the large language model. This is called supervised learning.
Most AI products are built using a much more manual, supervised learning process than unsupervised learning. In any case, the magnitude of data needed for modern industrial-scale AI cannot be understated. ChatGPT’s 2020 large language model, GPT-3, was trained using hundreds of billions of words from websites, books, and articles.
Figure 3: Data sources used to train OpenAI’s GPT-3 large language model in 2020.
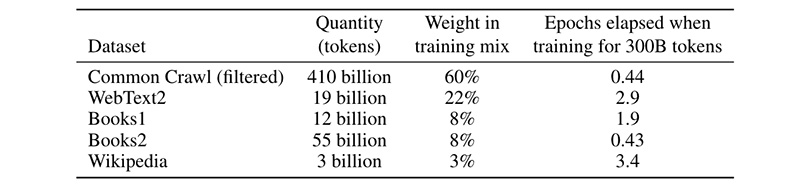
Table C.1 Datasets used to train GPT-3. “Weight in training mix” refers to the fraction of examples during training that are drawn from a given dataset, which we intentionally do not make proportional to the size of the dataset. As a result, when we train for 300 billion tokens, some datasets are seen up to 3.4 times during training while other datasets are seen less than once.
How large language models are made
So, at the beginning of the production process for large language models, data workers must gather, label, correct, and sort massive amounts of data. For one, the websites, books, articles, photographs, videos, and other media used in training datasets were created by working people who could be anywhere in the world. Researchers and corporations justify their use of these copyrighted works as fair use, but many writers disagree in court, especially considering the models’ ability to reproduce copyrighted works verbatim. What’s more, those who are employed for this purpose often have few other options, like prisoners, refugees, and the poor in any particular region of the world. The work itself is shredded into millions of small tasks and sent to this global workforce, employed either as or by contractors for larger corporations that actually sell the AI product. These workers may work together in a makeshift office or be geographically isolated from one another in a digital workspace. Each task takes between a few seconds and a couple of minutes to complete.
In the middle of the production process, the AI models are trained in large data centers that house computers dedicated to carrying out massive amounts of computation. GPT-3, for example, was estimated to have required 1.287 gigawatt hours of energy to train, more energy than 100 average U.S. homes use in a year. Only at the end of the production process, when the AI is deployed to be used by the customer, does work once again resemble the usual office environment.
A day in the life
The work day is an exercise in the separation of the mind from the body, a ritual sacrifice of life at the altar of the virtual. The workers’ mental capacity is all the boss wants; it’s just a historical accident that workers’ bodies must be used to channel their soul into the machine, into capital. The workstation is entirely static, and workers are discouraged from working from anywhere but home for the sake of defending the company’s intellectual property. For the length of the work day, everything the data labeler does is tied to a single number: the number of pieces of data they have labeled. They are stuck in place for hours, nearly disembodied but for the strain in their wrists, fingers, eyes, backs, and heads, completing tasks. An entry in my work journal describing the ritual is recorded below.
9 AM: My partner, who also works from home, starts most days with a brief and gentle yoga session. It’s good for physical and mental health, and given that sitting in an office or on the way to or from an office all day kills, I’m often inclined to join her to affirm my life. But the work day has begun, and the all-seeing eye of management casts its gaze on its virtual domain, manifested as my work laptop. So I turn my partner’s offer of health down, slide the cool work laptop to the center of my desk, and log in. Check the queues: there is no work to be done yet, but I have to be at my laptop for the whole work day, just in case. The ~30 of us who were brought on board in January are assigned to various queues full of microtasks that number into the hundreds and thousands. There are about 70 of us part-time, temporary data labelers split into teams as needed on a day-by-day, week-by-week basis. Data labelers are asked about any special skills we have (e.g., “Can you program computers? Do you have experience as a journalist or fact-checker?”) so that we may be sorted into work groups as the full-time engineering team makes labeling work available.
10 AM: Work is incoming. The formula for onboarding is set. Engineering sets up a queue for a particular type of data to be labeled. One day we may be guiding the computer in recognizing important objects in images; another day we may be teaching it to write code. While the queue is being set up, someone on the engineering team writes a detailed set of instructions for the data labelers to carry out. It is critical that the data labelers properly understand and carry out those instructions, because the AI product is guaranteed to work poorly if the data is labeled poorly. We are briefly tested on our ability to follow instructions by labeling a data set that the engineering team has already labeled, then comparing our answers. If we pass the test, then we are allowed to label real data that the model will use in its calibration process. If we fail, we have to report our failure and wait for another queue.
11 AM: Wait for engineering to add me to the proper work team. Because I work on the backend of an AI product, my work hours are not always full to the brim with work, unlike Facebook content moderators. Our work comes in large bursts that keep us busy for weeks at a time, with a day here or there spent working on high-priority tasks off the main queue. In the meantime, anxiety mounts as we’re unsure whether management really doesn’t have work for us or we’ve fallen through the cracks. It’s hard to use the free time to do anything substantial because it’s not truly free: one has to constantly check in to make sure you haven’t been quietly assigned work while you weren’t paying attention, which happens more often than one would think.
12 PM: At last, the engineering team adds me to the queue. In the digital company of 50 reviewers, I get to work helping AI interpret questions about images and their contents. Every task we complete and the rate at which we complete it is tracked, and there is a quota, sometimes unspoken, that we are expected to meet. It’s unclear who estimates the quota or how the estimate is calculated. If an individual fails to meet the quota, the managers may retrain or terminate them. If we aren’t meeting the quota as a collective, we promptly get questioned by the engineering team about why it’s taking so long. So far, when this happens, we are shifted to another task while the engineers try to work around the issue.
1 PM: Again I glance over to the clock and notice my shift is finally over. Bittersweet, as I need more hours for more money, but the work is grueling. When I interviewed for the position, I asked what new workers least expected about the job. The response was something like: “People are surprised by how boring and exhausting the work can be. That’s actually why the company decided not to hire full-time workers for this role this time around.”

The way forward
Much has been written about the ultimate effect of AI on the world. The danger of AI is not that it will someday use its blind reasoning and vast capability for calculation to impose its inhuman will on us — capitalism does that well enough in the current moment.
With us today is the drive to generalize the abilities of AI to perform all work and thus reduce human activity to the mere mirth of the capitalists who own AI. This drive leads to people recoiling in fear of this complex of workers and technologies, demanding from its creators and proponents the barest social guarantees of well-being, like jobs, healthcare, and housing.
But at its worst, AI simply produces a strange, tireless worker. There is nothing for the worker to fear but the worker’s own reflection, with limbs and face contorted by its utter subservience to capital. The danger is that workers may not muster the strength to free themselves, instead pouring their soul into capital such that it is nearly impossible to retrieve, making eternal the process of their own oppression. By organizing the section of the working class directly employed to build AI, we seize a great deal of influence on how the technologies are used.
Some claim whether tech workers occupy a class position more closely tied to that of managers than workers. With rolling layoffs in the tech industry since 2022, those claims no longer hold water. The objective reality of tech work became painfully clear: the industry has found a transformative technology that opens the definition of tech worker far beyond the stereotypical white male Silicon Valley startup founder. Most tech workers do not make six-figure cash salaries with bonuses to match; most do not have peace of mind at work, let alone a path to better employment from their current; most — especially those who aren’t white men — are temporary contract workers. If tech workers once located their power by staying close to management, they were compelled by their bosses to abolish that state of affairs by automating their way to maximum profits.
The way forward is to support organizing tech workers and make the case to labor organizations that tech workers need more resources to organize resistance to the unchecked exploitation of the industry. We can anticipate the next stages of development in the tech industry in the U.S. and abroad. The tech industry extends into all other industries and its leading corporations openly intend to force the working class into precarious, yet to be organized, forms of work like data labeling in AI and so many other jobs like that. The failure of labor to organize tech threatens to be one of the great failures of the early 21st century. Thus far, only a handful of national unions have dedicated campaigns to organizing tech workers, Communications Workers of America, the Office and Professional Employees International Union, and the United Steel Workers among them. But we must do more and can do more. As the titans of the digital Gilded Age threaten to force the working class to dissolve into capital, and as the conditions for the future revolution develop, we must prepare to seize the moment.
Images: Microsoft Bing Maps’ datacenter by Robert Scoble (CC BY 2.0 DEED) / Stressed at work by Ciphr (CC BY 2.0 DEED); Probabilistic model for “the quick brown fox jumps over the lazy dog,” image courtesy of Kei Kebreau; Probabilistic model for the Communist Manifesto, Ibid.; What is Data Labeling and What is the Role of a Data Labeler? by Brainstormingbox (Twitter/X); A Frustrated Businessman in Front of a Laptop by Yan Krukau (via pexels.com)
 Join Now
Join Now